Tokens
Modern large language models (LLMs) are typically based on a transformer architecture that processes a sequence of units known as tokens. Tokens are the fundamental elements that models use to break down input and generate output. In this section, we'll discuss what tokens are and how they are used by language models.
What is a token?
A token is the basic unit that a language model reads, processes, and generates. These units can vary based on how the model provider defines them, but in general, they could represent:
- A whole word (e.g., "apple"),
- A part of a word (e.g., "app"),
- Or other linguistic components such as punctuation or spaces.
The way the model tokenizes the input depends on its tokenizer algorithm, which converts the input into tokens. Similarly, the model’s output comes as a stream of tokens, which is then decoded back into human-readable text.
How tokens work in language models
The reason language models use tokens is tied to how they understand and predict language. Rather than processing characters or entire sentences directly, language models focus on tokens, which represent meaningful linguistic units. Here's how the process works:
-
Input Tokenization: When you provide a model with a prompt (e.g., "LangChain is cool!"), the tokenizer algorithm splits the text into tokens. For example, the sentence could be tokenized into parts like
["Lang", "Chain", " is", " cool", "!"]. Note that token boundaries don’t always align with word boundaries.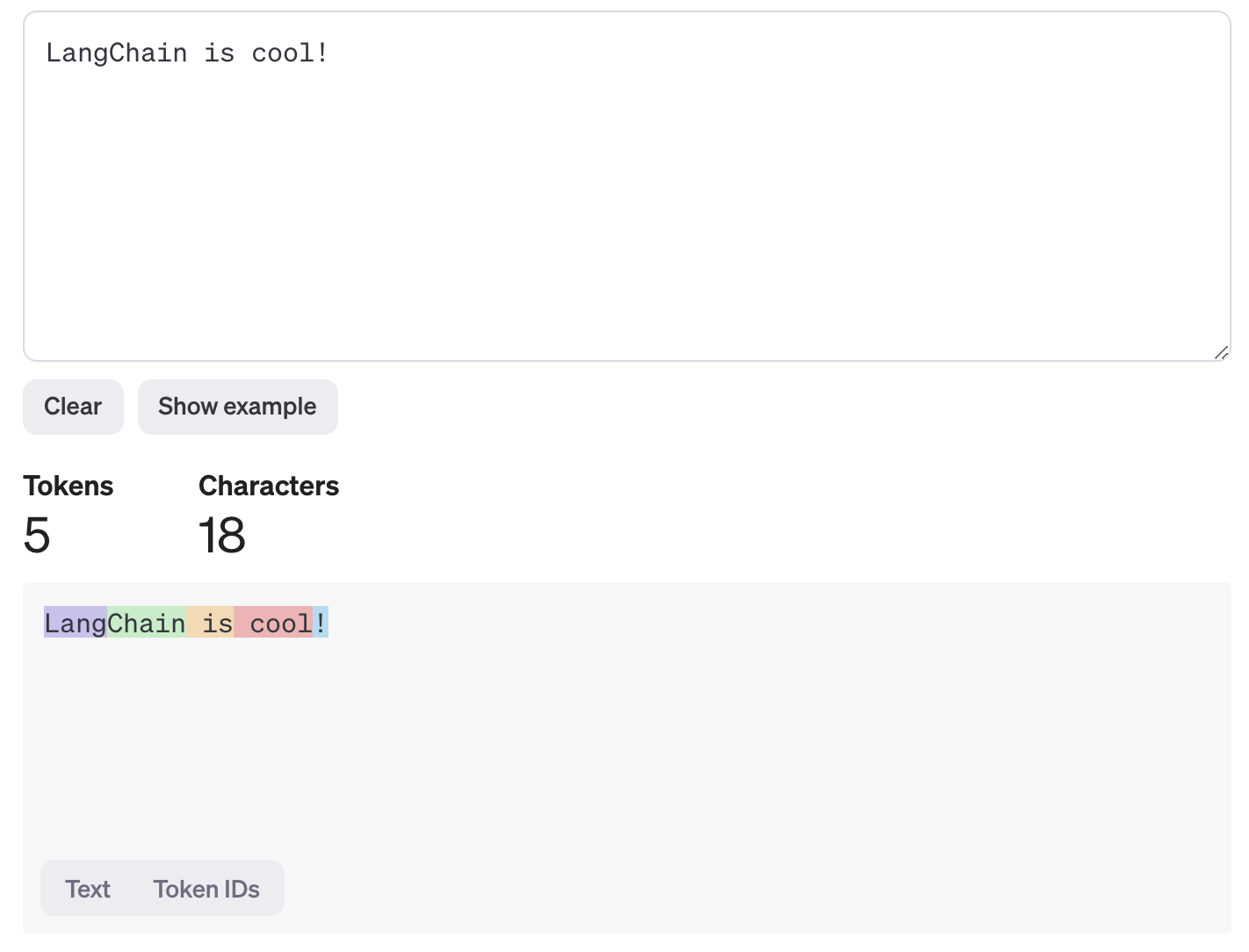
-
Processing: The transformer architecture behind these models processes tokens sequentially to predict the next token in a sentence. It does this by analyzing the relationships between tokens, capturing context and meaning from the input.
-
Output Generation: The model generates new tokens one by one. These output tokens are then decoded back into human-readable text.
Using tokens instead of raw characters allows the model to focus on linguistically meaningful units, which helps it capture grammar, structure, and context more effectively.
Tokens don’t have to be text
Although tokens are most commonly used to represent text, they don’t have to be limited to textual data. Tokens can also serve as abstract representations of multi-modal data, such as:
- Images,
- Audio,
- Video,
- And other types of data.
At the time of writing, virtually no models support multi-modal output, and only a few models can handle multi-modal inputs (e.g., text combined with images or audio). However, as advancements in AI continue, we expect multi-modality to become much more common. This would allow models to process and generate a broader range of media, significantly expanding the scope of what tokens can represent and how models can interact with diverse types of data.
In principle, anything that can be represented as a sequence of tokens could be modeled in a similar way. For example, DNA sequences—which are composed of a series of nucleotides (A, T, C, G)—can be tokenized and modeled to capture patterns, make predictions, or generate sequences. This flexibility allows transformer-based models to handle diverse types of sequential data, further broadening their potential applications across various domains, including bioinformatics, signal processing, and other fields that involve structured or unstructured sequences.
Please see the multimodality section for more information on multi-modal inputs and outputs.
Why not use characters?
Using tokens instead of individual characters makes models both more efficient and better at understanding context and grammar. Tokens represent meaningful units, like whole words or parts of words, allowing models to capture language structure more effectively than by processing raw characters. Token-level processing also reduces the number of units the model has to handle, leading to faster computation.
In contrast, character-level processing would require handling a much larger sequence of input, making it harder for the model to learn relationships and context. Tokens enable models to focus on linguistic meaning, making them more accurate and efficient in generating responses.
How tokens correspond to text
Please see this post from OpenAI for more details on how tokens are counted and how they correspond to text.
According to the OpenAI post, the approximate token counts for English text are as follows:
- 1 token ~= 4 chars in English
- 1 token ~= ¾ words
- 100 tokens ~= 75 words