Embedding models
This conceptual overview focuses on text-based embedding models.
Embedding models can also be multimodal though such models are not currently supported by LangChain.
Imagine being able to capture the essence of any text - a tweet, document, or book - in a single, compact representation. This is the power of embedding models, which lie at the heart of many retrieval systems. Embedding models transform human language into a format that machines can understand and compare with speed and accuracy. These models take text as input and produce a fixed-length array of numbers, a numerical fingerprint of the text's semantic meaning. Embeddings allow search system to find relevant documents not just based on keyword matches, but on semantic understanding.
Key concepts
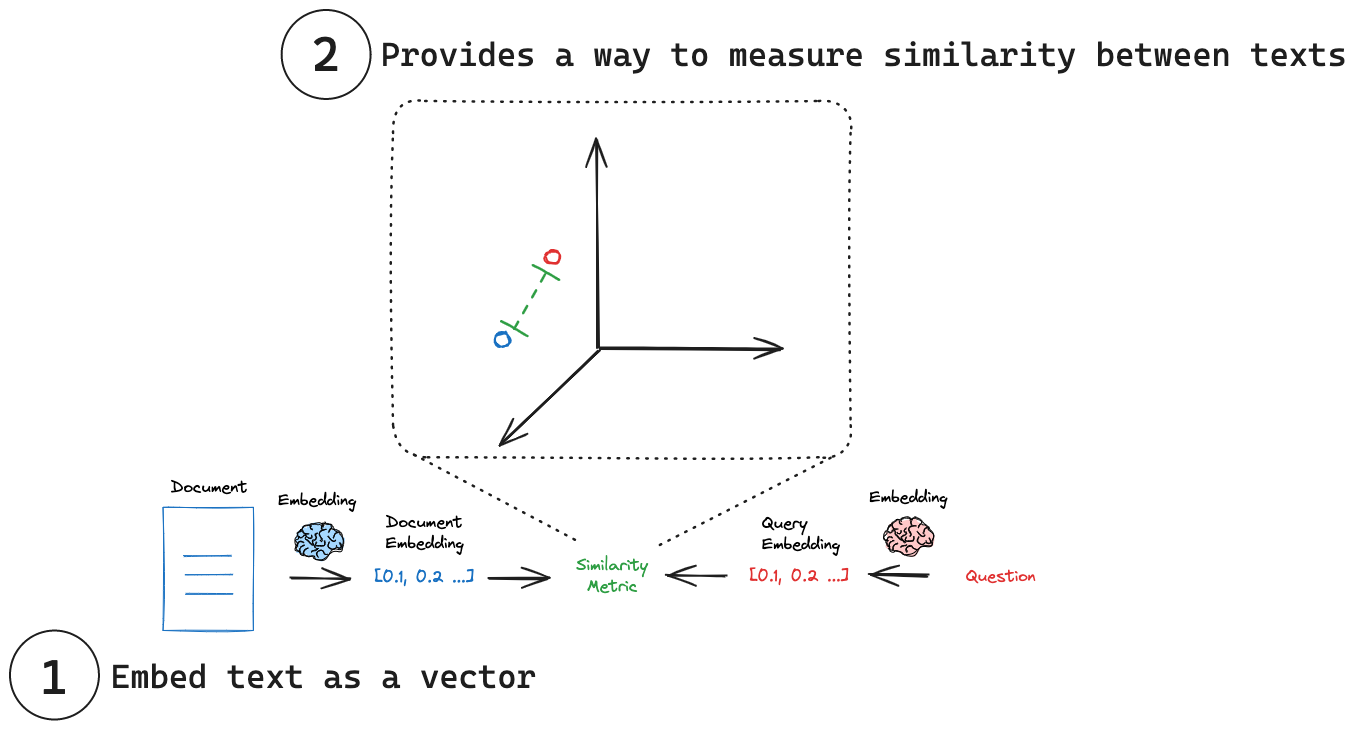
(1) Embed text as a vector: Embeddings transform text into a numerical vector representation.
(2) Measure similarity: Embedding vectors can be compared using simple mathematical operations.
Embedding
Historical context
The landscape of embedding models has evolved significantly over the years. A pivotal moment came in 2018 when Google introduced BERT (Bidirectional Encoder Representations from Transformers). BERT applied transformer models to embed text as a simple vector representation, which lead to unprecedented performance across various NLP tasks. However, BERT wasn't optimized for generating sentence embeddings efficiently. This limitation spurred the creation of SBERT (Sentence-BERT), which adapted the BERT architecture to generate semantically rich sentence embeddings, easily comparable via similarity metrics like cosine similarity, dramatically reduced the computational overhead for tasks like finding similar sentences. Today, the embedding model ecosystem is diverse, with numerous providers offering their own implementations. To navigate this variety, researchers and practitioners often turn to benchmarks like the Massive Text Embedding Benchmark (MTEB) here for objective comparisons.
- See the seminal BERT paper.
- See Cameron Wolfe's excellent review of embedding models.
- See the Massive Text Embedding Benchmark (MTEB) leaderboard for a comprehensive overview of embedding models.
Interface
LangChain provides a universal interface for working with them, providing standard methods for common operations. This common interface simplifies interaction with various embedding providers through two central methods:
embed_documents: For embedding multiple texts (documents)embed_query: For embedding a single text (query)
This distinction is important, as some providers employ different embedding strategies for documents (which are to be searched) versus queries (the search input itself).
To illustrate, here's a practical example using LangChain's .embed_documents method to embed a list of strings:
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
(5, 1536)
For convenience, you can also use the embed_query method to embed a single text:
query_embedding = embeddings_model.embed_query("What is the meaning of life?")
- See the full list of LangChain embedding model integrations.
- See these how-to guides for working with embedding models.
Integrations
LangChain offers many embedding model integrations which you can find on the embedding models integrations page.
Measure similarity
Each embedding is essentially a set of coordinates, often in a high-dimensional space. In this space, the position of each point (embedding) reflects the meaning of its corresponding text. Just as similar words might be close to each other in a thesaurus, similar concepts end up close to each other in this embedding space. This allows for intuitive comparisons between different pieces of text. By reducing text to these numerical representations, we can use simple mathematical operations to quickly measure how alike two pieces of text are, regardless of their original length or structure. Some common similarity metrics include:
- Cosine Similarity: Measures the cosine of the angle between two vectors.
- Euclidean Distance: Measures the straight-line distance between two points.
- Dot Product: Measures the projection of one vector onto another.
The choice of similarity metric should be chosen based on the model. As an example, OpenAI suggests cosine similarity for their embeddings, which can be easily implemented:
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)
- See Simon Willison’s nice blog post and video on embeddings and similarity metrics.
- See this documentation from Google on similarity metrics to consider with embeddings.
- See Pinecone's blog post on similarity metrics.
- See OpenAI's FAQ on what similarity metric to use with OpenAI embeddings.